I came across an interesting comment in an article by Alan Davies on The Urbanist. Davies discusses Ian Walker’s overtaking distance study which found a statistically significant association with helmet wearing and motor vehicle overtaking distance. Like a study I published last year, Davies did not find the results convincing with regards to helmets but found other factors like vehicle size and the cyclist’s position in the lane more important.
As expected, there were several comments defending Walker’s conclusions among those with anti-helmet views. A comment left by RidesToWork (who I believe is Bicycle Helmet Research Foundation editorial board member Dorothy Robinson) states
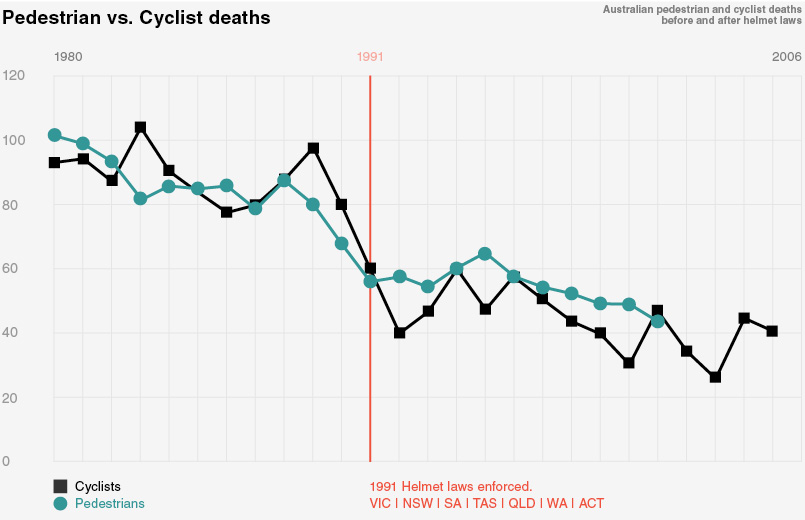
Many readers of this blog appear keen to dismiss the arguments than the difference in passing room might make a difference. Yet they don’t apply the same critical thinking to claims about helmet laws – such as Figure 2 of http://www.cyclehelmets.org/1228.html The effect, if there is one, is nothing like as clear as the effect of helmet wearing on passing distance.
I found this comment dubious, in part, because it links to an unfounded and misleading criticism of one my articles, but also because it’s quite a bold statement comparing the results from two very different studies. Walker’s analysis was a 2×5 ANOVA for motor vehicle overtaking distance while cycling in the UK with 2 levels of helmet wearing and 5 levels of distance to the kerb. Our study, used Poisson regression to model the rate of head and limb injury hospitalizations in NSW in the the three year period surrounding the helmet laws in 1991.
Note the Figure 2 mentioned in the comment has been dubiously manipulated through rescaling and shifting two time series so they overlap to produce a seemingly null effect. This seems to be a common tactic by anti-helmet advocates as I’ve discussed before here and here.
Regarding Robinson’s claim, the question is how can someone claim the results from one study are more “clear” compared to another, disparate study?
One method is to compare their effect sizes (ES) on some common scale. It is well known that large sample sizes can make unimportant differences statistically significant (the opposite is true for small sample sizes, i.e., important differences are not statistically significant). Take the one sample z-test for the population mean  , for example. The right tailed p-value converges to 0 as n tends to infinity for fixed values of
, for example. The right tailed p-value converges to 0 as n tends to infinity for fixed values of 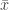 and
and  , i.e.,
, i.e.,

As a result, a significant p-value is possible even when is infinitesimally close to  . For that reason, it is important not to overpower a study by choosing an excessively large sample size (Walker did just that in his study computing sample size based on 98% power instead of the usual 80% or 90%). Effect sizes are essentially the observed test statistic without the influence of sample size (conversely, it can be used to compute sample size a priori).
. For that reason, it is important not to overpower a study by choosing an excessively large sample size (Walker did just that in his study computing sample size based on 98% power instead of the usual 80% or 90%). Effect sizes are essentially the observed test statistic without the influence of sample size (conversely, it can be used to compute sample size a priori).
Jacob Cohen defined the difference in sample means divided by the sample standard deviation as an effect size for the two sample t-test, i.e.,
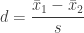 .
.
Cohen further proposed operationally defined values of 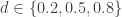 as small, medium and large effect sizes respectfully[1]. The reasoning given by Cohen regarding these values is
as small, medium and large effect sizes respectfully[1]. The reasoning given by Cohen regarding these values is
My intent was that medium ES represent an effect likely to be visible to the naked eye of a careful observer… I set small ES to be noticeably smaller than medium but not so small as to be trivial, and I set large ES to be the same distance above medium as small was below it.
The results from both Walker’s data and our study on mandatory helmet legislation can be converted to Cohen’s d. An  statistic with 1 numerator degree freedom can be converted to Cohen’s d by
statistic with 1 numerator degree freedom can be converted to Cohen’s d by
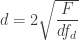
For helmet wearing, Walker reported  which correponds to
which correponds to 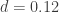 . This categorizes helmet wearing as a trivial, and therefore unimportant, effect size by Cohen’s definition.
. This categorizes helmet wearing as a trivial, and therefore unimportant, effect size by Cohen’s definition.
It is also possible to convert to Cohen’s d for a linear model with a binary predictor  (takes on values 0 or 1) and corresponding coefficient
(takes on values 0 or 1) and corresponding coefficient  as
as

where 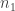 and
and 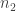 are group sample sizes. In our re-analysis of Walker’s data, the adjusted effect of helmet wearing for Walker’s data is -0.058 respectively. There were 1206 and 1149 overtaking events when not wearing or wearing a helmet respectively which translates to
are group sample sizes. In our re-analysis of Walker’s data, the adjusted effect of helmet wearing for Walker’s data is -0.058 respectively. There were 1206 and 1149 overtaking events when not wearing or wearing a helmet respectively which translates to 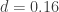 (a more respectable value, although I doubt Walker or Robinson would ever agree with our results). Note that in my analysis, I did not use a square root transformation or remove 35 observations as Walker did as these considerations are unnecessary given the large sample size.
(a more respectable value, although I doubt Walker or Robinson would ever agree with our results). Note that in my analysis, I did not use a square root transformation or remove 35 observations as Walker did as these considerations are unnecessary given the large sample size.
In our re-analysis of Walker’s paper, we also performed logistic regression to assess whether close overtaking was associated with helmet wearing as this is more relevant to cycling safety. Using the one meter rule as a cut point, we estimated a non-significant adjusted odds ratio of 1.13 (p=0.54). Odds ratios can also be transformed to Cohen’s d by
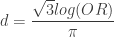
Using the adjusted odds ratio, we get 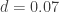 which is again trivial by Cohen’s definition.
which is again trivial by Cohen’s definition.
In our paper regarding mandatory helmet legislation, we reported a decline in bicycle related head injury relative to limb injury at the time of the NSW helmet law of 27.5% or 31% depending on whether arm or leg injuries were used as the comparator. These results can also be written as rate ratios of 0.725 or 0.69 respectively. If we assume the rate ratio here is equivalent to an odds ratio, Cohen’s d is 0.18 and 0.20 respectively.
Our analysis made the implicit assumption that no cyclist wore helmets pre-law and all cyclists wore helmets post-law. If, instead, the comparison was relative to the approximate 55% increase in helmet wearing in NSW, we get rate ratios of 0.56 and 0.51 and transformed Cohen d’s of 0.32 and 0.37.
I also published a paper last year that proposed operationally defined effect sizes for odds ratios that did not require transformation to Cohen’s d or make distributional assumptions regarding effect sizes. These were 1.22, 1.86 and 3.00 for small, medium and large odds ratios (or, equivalently, 0.82, 0.54 and 0.33).
These results suggest the helmet wearing effect from Walker’s data is trivial and the effect of helmet legislation is about a medium effect size. Of course, these results are from one cyclist and from one Australian state. So, over-generalizations should not be made without more data. However, note that Walker did repeat aspects of his first study comparing seven types of cyclists. The CASUAL type was the only one without a helmet with a mean overtaking distance of 117.61cm. This was approximately dead center of the means (range: 114.01cm – 122.12cm) suggesting the trivial helmet effect size from the original study was no coincidence.
- Cohen J (1992) A power primer. Psychological Bulletin 112: 155–159.



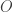 are the observed frequencies and
are the observed frequencies and  is the expected frequency under an assumption of independence, i.e., no relationship between helmet legislation and the amount of cycling. These residuals are asymptotically normal, so residuals with absolute value greater 1.96 may be considered “statistically significant”. The sign would indicate observing more than expected (if positive) or less than expected (if negative).
is the expected frequency under an assumption of independence, i.e., no relationship between helmet legislation and the amount of cycling. These residuals are asymptotically normal, so residuals with absolute value greater 1.96 may be considered “statistically significant”. The sign would indicate observing more than expected (if positive) or less than expected (if negative).
 has four categories and therefore gets estimated by three dummy variables.
has four categories and therefore gets estimated by three dummy variables. and
and 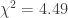 ,
,  and
and  . This result could be influenced by the need to estimate the number of cases from a plot. We can assess the influence of this estimate by repeating the analysis for other values near 900. Choosing values from 890 to 910 results in the plot of p-values below.
. This result could be influenced by the need to estimate the number of cases from a plot. We can assess the influence of this estimate by repeating the analysis for other values near 900. Choosing values from 890 to 910 results in the plot of p-values below.